SEO пагинация: как сделать правильно и выявить основные ошибки.
Польский писатель Януш Вишневский однажды заметил: «Интернет – это джунгли, и иногда он напоминает свалку информации». Худшее из возможных решений веб-мастера – перегрузить страницы данными, завалить роботов и посетителей грудой контента, который еще и загружаться будет сотню световых лет.
По канонам SEO ресурс должен быть структурированным, легким, быстрым, понятным. Пагинация – возможность разбить огромный пласт данных на блоки, которые будут отображаться дозированно либо сегментироваться постранично. С помощью пагинатора – навигационного блока – удается сделать понятный «путеводитель» или «поисковик» по частям одного большого целого. Пагинацию можно наблюдать на главных страницах сайтов и разделов.

Возможны разные форматы исполнения: алфавитный, календарный. Пагинация необходима ресурсам с большим объемам данных (интернет-магазинам, крупным информационным порталам). Грамотно оформленное «деление» массива – удобство работы с сайтом, оптимальная скорость загрузки страниц. На языке SEO это значит повышение юзабилити и поведенческих факторов, улучшение ранжирования. Осталось понять, как сделать пагинацию правильно и избежать ошибок.
SEO-составляющая пагинации
Само деление массива не выглядит сверхсложной задачей, но рабочая пагинация – одно, а оптимизированная – другое. Разбитый на блоки контент остается важным элементом сайта, поэтому нужно считаться с возможными проблемами при раскрутке. SEO-тонкости пагинации, которые могут огорчить веб-мастера:
- Дубли. Страницы пагинации – что братья-близнецы: очень похожий контент, повторяющиеся title. Если при индексации роботы посчитают страницы дублями, релевантность и уникальность упадут. Санкции тоже не исключены.
- Некорректные сканирование и индексация. Краулинговый бюджет роботов ограничен. При изучении страниц в рамках апдейта краулер может потратить все «очки» на скан десятых, двадцатых и т. д. страниц пагинации. На основании анализа проводится индексация и формируется поисковая выдача. Цель оптимизатора – добиться в первую очередь индексации полезных и релевантных страниц.
Есть польза от ранжирования тринадцатой страницы каталога товаров вместо главной? Нет. Релевантна ли такая страница запросам пользователей на 100%? Частично. Повысится ли bounce rate? Вполне вероятно! Если бюджета на главные страницы не хватит, в выдачу роботы их не отправят. Жирный минус для раскрутки ресурса.
В итоге пользователи могут и не узнать обо всем спектре товаров и услуг сайта. Никто не будет пробиваться через дебри каталогов интернет-магазина, если в выдаче не будет ссылок на ключевые страницы.
- Повышение нагрузки на сайт. Справка Google Search Console предупреждает: сканирование огромного массива страниц пагинации ведет к увеличению нагрузки. Это может вызвать нестабильную работу ресурса и снижение скорости.
Анализ проблем с пагинацией
Совершенству нет предела, но в случае c SEO догадки лучше подтверждать фактами. В контексте работы с пагинацией выявить критические ошибки несложно. Если в проиндексированном роботами массиве появятся дубли метаданных (страниц) – сигнал тревожный.
Понять, что дело в неправильной настройке пагинации, можно через поиск дубликатов. Рабочие способы для Google и Яндекс:
- Воспользоваться командой site:. В поисковой строке Google нужно прописать site:example.ru, где example.ru – домен вашего сайта. Поисковик отразит в выдаче все индексируемые страницы. Дубли не останутся незамеченными. Способ прост и актуален для небольших ресурсов.
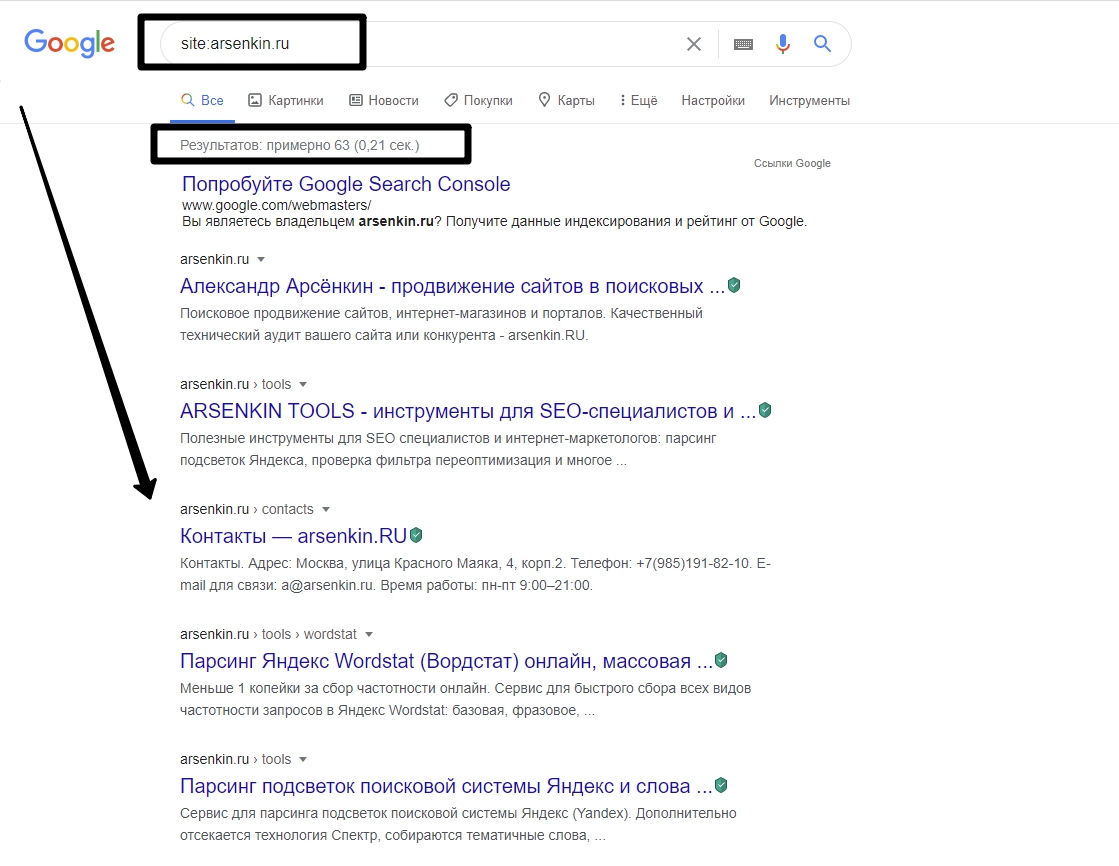
- Проверить ресурс специализированными программами-краулерами – Xenu, Screaming Fog Seo Spider, Netpeak Spider. Работа проходит автоматически по понятным алгоритмам. Пошаговый мануал на примере Xenu:
- Открыть вкладку Check URL.
- Вписать доменное имя проверяемого сайта.
- Отсортировать результаты по
- Обратиться к панелям поисковых систем для веб-мастеров. Путь к разделу в Яндекс.Вебмастере: Индексирование – Страницы в поиске – Исключенные страницы – Статус «Дубль». Для Google Search Console: Покрытие – Исключено.
- Проанализировать ключевые URL на дубликаты в онлайн-сервисах. Полезный ресурс: https://apollon.guru/duplicates/.
Косвенно на наличие дублей указывают санкции поисковых систем. Вкупе с другими грубыми ошибками дубликаты приводят к наложению на сайт фильтров. Опытные SEO-специалисты помнят легендарный Google Supplemental – «дополнительные результаты поиска», куда многочисленные дубли отправлялись в ссылку.
Стратегии пагинации
В контексте SEO-оптимизации пагинация (деление массива) должна:
- упрощать взаимодействие пользователей с сайтом;
- повышать поведенческие факторы и ранжирование ресурса;
- способствовать корректной поисковой индексации.
Все методики SEO-пагинации базируются на одной из идей:
- Закрыть страницы пагинации от индекса.
- Оставить пагинацию открытой для индексации.
Сторонников в обоих лагерях много. Рассмотрим техническую реализацию и инструменты разных подходов.
Основы «открытых» стратегий:
- Уникальные title для страниц пагинации.
- Исключение дублей текстового контента.
- 301 редирект, чтобы исключить дубли главных страниц.
| Через robots.txt | Через meta name robots | С помощью rel=»canonical» | |
|
Закрытые системы |
Использование директив Disallow: */page/.
Роботы не попадут на страницы, товарные позиции почти не будут индексироваться |
<meta name=»robots» content=»noindex» />
Глубокое скрытие без шансов увидеть ссылки на страницы пагинации даже в «закрытой выдаче» |
Указать каноничные страницы разделов.
Скрывает от индексирования все страницы пагинации, кроме главных. Максимально близкий к рекомендациям Google вариант |
Немного теории. При пагинации подразумевается, что должна быть главная (каноническая) страница. Долгие годы веб-мастеры свято верили, что для Google актуален «классический набор» – атрибуты rel=»canonical», rel=next и rel=prev. Next и prev давали роботам понять, где главная страница, а где страницы пагинации (дубли). В марте 2019 Google объявил, что rel=next и rel=prev не поддерживаются уже много лет.

Правильная стратегия пагинации в 2020
Google обновил корневые алгоритмы ранжирования, Яндекс не отстает в инновациях. Современные технологии меняются, но ключевой посыл поисковых систем остается прежним: нужно понимать, чего желают пользователи, и подстраиваться под них.

Google еще в 2019 году посоветовал… отказаться от пагинации. «Старый» многостраничный формат не является нарушением, но исследование показало: людям нравится модель single-page content.
Суть: весь контент размещается на одной странице, внедряется функционал динамической (ленивой) загрузки с помощью AJAX (Asynchronous Javascript and XML). Информация не генерируется и не загружается, пока она не станет нужна. На первом этапе посетитель видит часть контента. Остальное подгружается:
- При скроллинге. Поэтапная загрузка. Встречается на сайтах СМИ, в интернет-магазинах, социальных сетях.
- После нажатия на активную кнопку («Показать еще», «Другие товары» и так далее) или элемент медиа. Под кнопками легко спрятать незначительную информацию. Если же контент важен для роботов и людей, вместо AJAX удобно применять обычный JS – с функцией отображения контента по требованию и предварительной загрузкой.
- В фоне. Неспешная подгрузка больших файлов во время изучения страницы. Может помочь ускорению сайта при вдумчивой реализации и постоянном анализе поведения посетителей.
Наглядные примеры реализации системы single-page content: https://meduza.io/ (на React.js), https://f.ua/, https://www.digitalagencylondon.co.uk/.
При стратегии single-page content краулеру отдается на откуп часть товаров и оптимизированный текст выделенного блока. Есть возможность «открыть» полную версию сайта (статические страницы) из кеша оперативной памяти сервера. Проверить, что из содержимого доступно роботам, можно в панелях веб-мастеров Google и Яндекса.
Краткие выводы:
- single-page content при правильной реализации повышает юзабилити (по данным Google);
- улучшение поведенческих факторов ведет к лучшему ранжированию в выдаче;
- для поисковой оптимизации SPC – главная модель и эффективная замена каноничной пагинации.
Реализация SPC требует участия программистов и серьезных финансовых трат. Для молодых (нераскрученных) проектов привычная пагинация остается безальтернативной. Придется вернуться к атрибутам и обратить пристальное внимание на рекомендации Яндекса и Google.
Общая позиция Google: краулеры должны сканировать страницы с дублированным контентом, но во избежание «нежелательных последствий» стоит помочь роботам с определением канонического URL. Если этого не сделать, роботы выберут страницу самостоятельно (необязательно правильно!).
Первая рабочая модель от Google – пагинация на страницу «Смотреть Все». Необходимо пометить все страницы пагинации (кроме главной) тегом <link> с атрибутом rel=»canonical».
При данном способе на канонической странице должен быть маркер «Смотреть все» / «View all». Пример тега: <link rel=»canonical» href=»http://site.ru/canonical-page»/>

Второй (альтеративный) способ настроить пагинацию под Google был показан на Google Webmaster Conference в Тель-Авиве в 2019 году:

Это метод пагинации с тегом rel=«canonical» (со всех страниц – на первую) и тегом noindex (для всех страниц). Уместно для интернет-магазинов: роботы не будут индексировать «части» пагинации, но будут сканировать товары каталога.
Общие рекомендации для обеих стратегий:
- не блокировать роботам доступ в robots.txt или другими путями (разрешить сканирование URL);
- задействовать внутреннюю перелинковку!
- проверять изменения сторонними краулерами.
Яндекс наравне с Goggle не поддерживает устаревшие теги rel=prev/next. Однако атрибут rel=»canonical» остался рабочим.

В июле 2019 года Платон дал развернутый комментарий относительно пагинации:
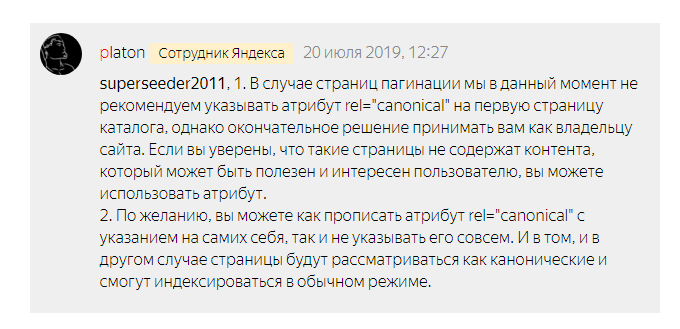
Стоит учитывать, что для Яндекса rel=»canonical» не инструкция к исполнению, а рекомендация! Робот волен проигнорировать атрибут из-за ошибки в указании или иных причин.
Заключение
Единой волшебной таблетки для всех ресурсов не существует. SPC финансово и технически реализовать сложно, пагинация с тегом rel=canonical на страницу «Смотреть все» может ухудшить производительность, модель с noindex формально идет вразрез со справочными материалами.
Яндекс и Google дают веб-мастерам выбор, но не готовые решения. Правильная стратегия – стратегия, которая не противоречит здравому смыслу. Стратегия, которая работает. Остальное – частные случаи.